
课程介绍
9大业务场景实战Hadoop+Flink,完成大数据能力进修视频教程。本课是一套大数据系统入门课程,从大数据基石——Hadoop讲起,再到Flink、ClickHouse、Hudi等热门核心技术,并通过一系列大型项目的实战,2大企业级项目,9种业务场景,实战中掌握大数据主流框架的应用能力。
相关推荐
极客时间 – 大数据训练营
大数据工程师2022版

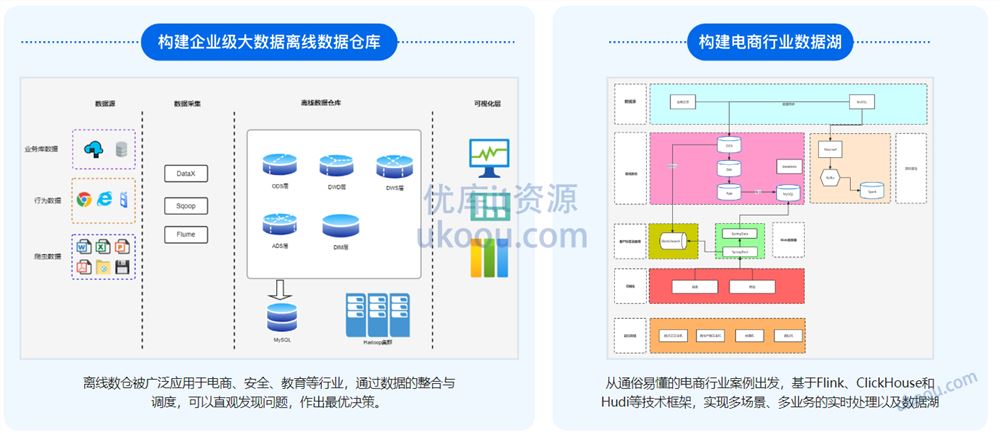
两个热门项目为基础,掌握十余种操作,打通从数仓构建到统计分析全流程
离线数仓项目:通过数据的整合与调度,可以直观发现问题,作出最优决策。
电商行业数据湖项目:从通俗易懂的电商行业案例出发,基于Flink、ClickHouse和Hudi等技术框架,实现多场景、多业务的实时处理以及数据湖
资源目录
.
1-高薪择业:为什么大数据行业更有前途?/
[1.7M] 1-1 本章概览
[ 10M] 1-2 什么是大数据
[8.3M] 1-3 大数据特点(4V)
[ 13M] 1-4 大数据带来的变革
[3.5M] 1-5 大数据应用场景
[7.5M] 1-6 大数据前景
[4.2M] 1-7 大数据学习方法论
2-急速入门大数据Hadoop:到底什么是Hadoop/
[1.5M] 2-1 本章概览
[ 24M] 2-2 Hadoop概述
[ 28M] 2-3 Hadoop发展史(了解)
[ 20M] 2-4 认识Hadoop三大核心组件
[ 19M] 2-5 大数据生态圈
[ 12M] 2-6 发行版的选择
3-大数据基石之文件系统:系统玩转分布式文件系统HDFS/
[3.1M] 3-1 本章概览
[ 31M] 3-2 初识HDFS
[ 81M] 3-3 HDFS假设和目标
[ 49M] 3-4 [重要!必掌握]HDFS架构
[ 18M] 3-5 文件系统命名空间
[ 40M] 3-6 副本因子及副本拜访策略
[ 13M] 3-7 [重要!必掌握]经典面试题
[5.0M] 3-8 HDFS优缺点
[ 21M] 3-9 Hadoop解压及重要目录讲解
[ 40M] 3-10 HDFS核心配置文件及免密码登陆
[ 46M] 3-11 HDFS启停(整体和单个)
[4.6M] 3-12 环境变量补充
[ 17M] 3-13 初识HDFS常用命令
[ 35M] 3-14 HDFS命令行操作之文件上传
[7.1M] 3-15 HDFS命令行操作之文件内容查看
[7.0M] 3-16 HDFS命令行操作之文件下载
[ 23M] 3-17 HDFS命令行操作之其他常用操作
[ 15M] 3-18 HDFS API开发之基本环境介绍
[ 24M] 3-19 jUnit快速入门
[ 14M] 3-20 jUnit生命周期(上)
[ 18M] 3-21 jUnit生命周期(下)
[ 56M] 3-22 HDFS API开发之创建文件夹
[ 35M] 3-23 HDFS API开发之上传文件
[ 35M] 3-24 HDFS API开发之参数优先级问题
[ 17M] 3-25 HDFS API开发之文件下载和重命名
[ 18M] 3-26 HDFS API开发之代码重构
[ 38M] 3-27 HDFS API开发之列表展示功能
[5.7M] 3-28 HDFS API开发之删除操作
[ 29M] 3-29 HDFS API开发之基于IO流的方式
[ 32M] 3-30 [重要!必掌握]经典面试题之HDFS写数据流程
[ 18M] 3-31 [重要!必掌握]经典面试题之HDFS读数据流程
[ 29M] 3-32 [重要!必掌握]NameNode&SecondaryNameNode工作机制(上)
[ 34M] 3-33 [重要!必掌握]NameNode&SecondaryNameNode工作机制(下)
[ 38M] 3-34 [重要!必掌握]DataNode工作机制
[ 22M] 3-35 安全模式
4-大数据基石之计算框架:系统玩转分布式计算框架MapReduce/
[ 10M] 4-1 本章概览
[ 23M] 4-2 初识MapReduce框架
[ 27M] 4-3 MapReduce框架的优缺点
[ 23M] 4-4 MapReduce思想(非常重要)
[8.0M] 4-5 MapReduce核心进程
[ 55M] 4-6 官方词频统计案例分析
[5.0M] 4-7 词频统计数据流图解
[ 32M] 4-8 MapReduce编程规范
[ 11M] 4-9 初识MR编程中的数据类型
[ 33M] 4-10 词频统计之自定义Mapper
[ 20M] 4-11 词频统计之自定义Reducer
[ 30M] 4-12 词频统计之自定义Driver
[ 28M] 4-13 词频统计之测试及重构
[ 62M] 4-14 词频统计之Mapper源码分析
[ 22M] 4-15 词频统计之Reducer源码分析
[ 26M] 4-16 词频统计之模板方法模式
[ 14M] 4-17 序列化概述
[ 27M] 4-18 序列化之JDK自带的序列化机制
[ 34M] 4-19 序列化之Data序列化机制
[ 32M] 4-20 Hadoop序列化之Writable接口详解
[ 38M] 4-21 Hadoop序列化之需求分析
[ 15M] 4-22 Hadoop序列化之自定义序列化类
[ 20M] 4-23 Hadoop序列化之自定义Mapper类
[ 14M] 4-24 Hadoop序列化之自定义Reducer类
[ 36M] 4-25 Hadoop序列化之自定义Driver类及测试
[ 16M] 4-26 Hadoop序列化之总结
[ 54M] 4-27 初识InputFormat&InputSplit
[ 20M] 4-28 InputSplit和Block的关系
[ 43M] 4-29 本地IDEA运行时InputSplit的大小测试
[ 11M] 4-30 认识FileInputFormat
[ 35M] 4-31 TextInputFormat编程
[ 52M] 4-32 KeyValueTextInputFormat编程
[ 36M] 4-33 NLineInputFormat编程
[ 78M] 4-34 DBInputFormat编程
[ 57M] 4-35 Partitioner功能及编程
[ 19M] 4-36 本地预计算Combiner意义
[ 38M] 4-37 本地预计算Combiner编程
[ 26M] 4-38 排序概述
[ 43M] 4-39 排序之全局排序编程
[ 22M] 4-40 排序之分区排序编程
[ 32M] 4-41 通过源码认识OutputFormat
[ 50M] 4-42 OutputFormat编程之输出数据到MySQL表中
[ 75M] 4-43 OutputFormat编程之自定义OutputFormat
[ 41M] 4-44 MapReduce全流程之MapTask工作原理
[ 18M] 4-45 MapReduce全流程之ReduceTask工作原理
[ 12M] 4-46 MapReduce全流程之Shuffle工作原理
[ 16M] 4-47 MapReduce全流程之加强
[ 14M] 4-48 场景题之group by需求分析
[ 30M] 4-49 场景题之group by功能开发及测试
[ 30M] 4-50 场景题之group by功能开发及测试
[6.8M] 4-51 场景题之distinct需求分析
[ 13M] 4-52 场景题之distinct功能实现及测试
[ 21M] 4-53 场景题之ReduceJoin需求分析
[ 21M] 4-54 场景题之ReduceJoin自定义序列化类
[ 66M] 4-55 场景题之ReduceJoin功能开发及测试
[8.7M] 4-56 场景题之ReduceJoin的弊端
[ 20M] 4-57 场景题之MapJoin原理分析
[ 62M] 4-58 场景题之MapJoin功能实现及测试
[ 41M] 4-59 基于MR编程开发核心组件系统性梳理
5-大数据基石之计算框架:系统玩转分布式计算框架MapReduce/
[1.8M] 5-1 本章概览
[ 17M] 5-2 YARN产生背景
[ 28M] 5-3 YARN架构核心组件
[ 64M] 5-4 [重要!必掌握]YARN核心组件职责
[ 19M] 5-5 [重要!必掌握]YARN工作原理
[ 11M] 5-6 YARN容错性
[5.9M] 5-7 以YARN为核心的生态系统
[ 11M] 5-8 YARN单节点部署
[ 28M] 5-9 提交官方自带案例到YARN上运行并认识YARN UI界面
[ 17M] 5-10 开启作业历史服务器
[ 54M] 5-11 YARN命令(掌握使用方法)
[ 29M] 5-12 [重要!必掌握]打包自己开发的作业到YARN上运行
[ 14M] 5-13 初识YARN调度器
[3.7M] 5-14 调度器之FIFO
[ 61M] 5-15 调度器之CapacityScheduler深入详解
[ 65M] 5-16 [重要!必掌握]调度器之CapacityScheduler队列配置及测试
[ 10M] 5-17 [重要!必掌握]调度器之CapacityScheduler优先级配置及测试
6-分布式协调框架ZooKeeper:ZK在Hadoop生态圈中的使用/
[2.4M] 6-1 本章概览
[ 15M] 6-2 初识ZK
[ 29M] 6-3 ZK角色及选举机制
[ 18M] 6-4 ZK在企业中的使用场景
[ 31M] 6-5 ZK单机单Server部署
[ 16M] 6-6 [重要!必掌握]ZK数据模型
[ 26M] 6-7 ZK命令行详解之创建
[ 12M] 6-8 ZK命令行详解之修改和删除
[4.4M] 6-9 初识ZK中的监听器
[ 15M] 6-10 [重要!必掌握]ZK监听器实操
[ 34M] 6-11 ZK命令行详解之四字命令
[7.3M] 6-12 ZK集群核心概念
[ 56M] 6-13 ZK单节点多Server部署及HA测试
7-轻松部署Hadoop集群环境:构建多个节点的Hadoop集群环境/
[2.6M] 7-1 本章概览
[9.6M] 7-2 从单机版引入到集群版
[ 30M] 7-3 Hadoop集群规划及准备工作
[ 40M] 7-4 Hadoop集群部署及测试
[ 81M] 7-5 Hadoop HA架构
[ 19M] 7-6 ZK分布式环境部署
[ 41M] 7-7 Hadoop集群HDFS HA配置及测试
8-SQL on Hadoop框架基础:急速入门数据仓库工具Hive和DDL&DML/
[3.8M] 8-1 本章概览
[ 19M] 8-2 Hive产生背景
[ 35M] 8-3 Hive是什么
[ 13M] 8-4 Hive的优缺点
[ 34M] 8-5 [重要!必掌握]Hive架构
[ 13M] 8-6 Hive部署架构
[ 24M] 8-7 经典面试题
[ 55M] 8-8 Hive部署及快速使用
[ 44M] 8-9 Hive中参数的设置和使用
[7.9M] 8-10 Hive访问方式之HS2&beeline
[ 14M] 8-11 [重要!必掌握]Hive中两个重要参数的用法
[ 12M] 8-12 [重要!必掌握]Hive数据模型
[ 38M] 8-13 DDL之创建数据库
[ 19M] 8-14 DDL之修改和删除数据库
[ 18M] 8-15 Hive数据类型&分隔符
[ 33M] 8-16 DDL之创建表语法
[ 29M] 8-17 DDL之创建表实操
[ 17M] 8-18 经典面试题分析之内部表
[ 16M] 8-19 经典面试题分析之外部表
[ 18M] 8-20 经典面试题分析之内外部表转换问题
[ 13M] 8-21 [重要!必掌握]经典面试题分析之内外部表对比及使用场景
[ 25M] 8-22 DDL之修改表实操
[ 12M] 8-23 经典面试题之drop和truncate的区别
[ 92M] 8-24 [重要!必掌握]DML之表数据加载的N种姿势
[ 13M] 8-25 经典面试题之为什么不使用insert values的写法呢
[ 25M] 8-26 DML之通过SQL导出数据
[ 15M] 8-27 [重要!必掌握]DML之export&import实操
[6.9M] 8-28 关于truncate的思考题
[ 11M] 8-29 分区表意义何在
[ 49M] 8-30 分区表实操之单分区表创建及数据加载
[9.6M] 8-31 分区表实操之多级分区表创建及数据加载
[ 45M] 8-32 场景题之使用动态分区解决复杂问题
[ 24M] 8-33 SQL查询之基础使用
[5.4M] 8-34 SQL查询之聚合函数的使用
[ 18M] 8-35 [重要!必掌握]SQL查询之分组函数的使用
[ 43M] 8-36 [重要!必掌握]SQL查询之JOIN的使用
9-SQL on Hadoop框架进阶:如何快速掌握Hive核心函数/
[2.1M] 9-1 本章概览
[ 30M] 9-2 动手实操复杂数据类型之array
[ 50M] 9-3 动手实操复杂数据类型之map
[ 14M] 9-4 动手实操复杂数据类型之struct
[8.6M] 9-5 如何去挖掘Hive中内置函数使用的方法论
[ 49M] 9-6 动手实操日期时间函数的使用
[ 11M] 9-7 动手实操取整相关函数的使用
[ 22M] 9-8 动手实操字符串相关函数的使用
[ 51M] 9-9 动手实操场景题之处理json数据
[ 16M] 9-10 动手实操URL函数的使用
[5.0M] 9-11 动手实操NVL函数的使用
[ 34M] 9-12 动手实操场景题之条件控制函数的使用
[ 12M] 9-13 [重要!必掌握]动手实操场景题之行列转换功能一
[ 18M] 9-14 [重要!必掌握]动手实操场景题之行列转换功能二
[9.5M] 9-15 [重要!必掌握]动手实操场景题之使用Hive完成wc统计
[5.6M] 9-16 初识Hive UDF函数
[ 13M] 9-17 动手实操开发自定义UDF函数之UDF实现类的开发
[ 31M] 9-18 [重要!必掌握]动手实操开发自定义UDF函数之UDF临时函数的注册和使用
[ 14M] 9-19 [重要!必掌握]动手实操开发自定义UDF函数之UDF永久函数的注册和使用
[ 15M] 9-20 自定义UDF扩展之如何集成Hive源码进行二次开发
[ 47M] 9-21 动手实操开发自定义UDF函数之新版本UDF开发及使用
[ 41M] 9-22 动手实操开发自定义UDTF函数开发及使用
[ 90M] 9-23 [重要!必掌握]窗口分析函数场景sum over的使用
[ 18M] 9-24 窗口分析函数场景NTILE的使用
[ 24M] 9-25 [重要!必掌握]窗口分析函数场景row_number&rank&dense_rank的使用
[ 37M] 9-26 窗口分析函数场景lag&lead的使用
[ 10M] 9-27 窗口分析函数场景firstvalue&lastvalue的使用
[ 29M] 9-28 窗口分析函数场景cume_dist&precent_rank的使用
[ 10M] 9-29 动手实操之窗口函数综合使用
10-SQL on Hadoop框架进阶:如何快速学会Hive调优/
[2.1M] 10-1 本章概览
[8.3M] 10-2 Hive调优概述
[ 38M] 10-3 Hive作业什么时候跑MR作业
[ 15M] 10-4 Hive作业如何以本地方式运行
[ 13M] 10-5 Hive严格模式带来的好处
[ 13M] 10-6 Hive4大by之order by
[ 24M] 10-7 Hive4大by之sort by
[ 28M] 10-8 Hive4大by之distribute by
[ 11M] 10-9 Hive4大by之cluster by
[ 17M] 10-10 Hive4大by总结
[9.2M] 10-11 Hive并行执行的适用场景
[ 19M] 10-12 Hive推测式执行能为我们带来的利弊
[ 23M] 10-13 Hive如何设置合理的MapTask数量
[ 23M] 10-14 Hive如何设置合理的ReduceTask数量
[ 13M] 10-15 分布式计算框架中产生数据倾斜的根本原因
[ 25M] 10-16 场景之groupby的数据倾斜解决方案
[ 26M] 10-17 场景之count(disintct)的数据倾斜解决方案
[ 40M] 10-18 场景之join的数据倾斜解决方案
11-日志收集利器Flume实战:如何使用Flume进行日志的收集/
[3.4M] 11-1 本章概览
[ 20M] 11-2 Flume产生背景
[ 15M] 11-3 采集vs收集
[ 32M] 11-4 初识Flume及学习姿势
[ 13M] 11-5 竞品分析
[5.5M] 11-6 发展史
[ 50M] 11-7 [重要!必掌握]Flume核心组件
[ 44M] 11-8 Flume Agent配置文件编写指南
[ 14M] 11-9 Flume部署
[ 35M] 11-10 Agent启动及测试
[7.8M] 11-11 数据传输基本单元Event
[ 82M] 11-12 实战之监控某个文件新增的内容并输出到HDFS
[ 76M] 11-13 实战之监控某个文件夹下新增的内容并输出到HDFS
[ 49M] 11-14 实战之监控某个文件夹下新增的内容并输出到HDFS分区中
[ 45M] 11-15 [重要!必掌握]实战之TAILDIR断点续传收集数据
[8.7M] 11-16 [重要!必掌握]生产场景理解
[ 53M] 11-17 avrosink和avrosource配对使用
[ 22M] 11-18 认识Channel Selector
[ 34M] 11-19 [重要!必掌握]实战之Channel Selector
[ 11M] 11-20 认识Sink Processor
[ 58M] 11-21 [重要!必掌握]实战之Sink Processor
12-高效简洁编程Scala入门:为什么大数据编程首选Scala语言&快速入门/
[认准一手完整 www.ukoou.com]
[3.6M] 12-1 本章概览
[ 27M] 12-2 Scala是什么
[9.0M] 12-3 学习Scala的意义何在
[ 15M] 12-4 Scala安装及快速使用
[ 15M] 12-5 Scala与JVM的关系
[ 23M] 12-6 基于IDEA构建Scala项目
[ 59M] 12-7 注释之论一个码农的自我修养
[ 46M] 12-8 标识符之论起名的艺术
[8.7M] 12-9 宏观了解Scala中的数据类型
[ 30M] 12-10 值和变量(注意理解第二个场景)
[ 32M] 12-11 数据类型
[ 22M] 12-12 数据类型转换
[ 35M] 12-13 [重要!必掌握]字符串操作
[ 21M] 12-14 实操之从控制台终端获取数据
[ 14M] 12-15 运算符的用法
[ 40M] 12-16 条件分支详解
[ 24M] 12-17 循环之while&dowhile
[ 18M] 12-18 循环之while以优雅的方式退出
[ 62M] 12-19 [重要!必掌握]循环之for
[8.6M] 12-20 通过场景引出方法
[ 29M] 12-21 [重要!必掌握]方法的定义和使用
[ 18M] 12-22 [重要!必掌握] 默认参数
[ 13M] 12-23 命名参数
[ 20M] 12-24 [重要!必掌握]变长参数
[ 21M] 12-25 数据类型补充之Unit&Null&Nothing
13-高效简洁编程Scala进阶:如何熟练掌握Scala面向对象编程&集合&模式匹配/
[认准一手完整 www.ukoou.com]
[6.1M] 13-1 本章概览
[ 18M] 13-2 面向对象三大特性
[ 12M] 13-3 [重要!必掌握]通过女朋友认识类和对象的关系
[ 39M] 13-4 定义类并通过反编译掌握属性对应的方法构成
[8.2M] 13-5 [重要!必掌握]占位符在Scala中的使用
[ 11M] 13-6 通过反编译掌握private关键字的使用
[ 32M] 13-7 构造器与附属构造器的使用及阅读源码
[ 56M] 13-8 继承&重写的使用及阅读源码
[ 37M] 13-9 抽象类的使用及阅读源码
[ 63M] 13-10 [重要!必掌握]伴生类&伴生对象
[ 33M] 13-11 从面试题说起case class&case object
[ 57M] 13-12 trait的定义及使用
[ 35M] 13-13 动态混入&自身类型
[ 35M] 13-14 包管理以及隐式转换导入
[ 23M] 13-15 [重要!必掌握]packageobject的使用
[ 38M] 13-16 类型转换&类型判断&类型别名
[ 14M] 13-17 枚举的使用
[ 16M] 13-18 App小技巧的使用
[ 38M] 13-19 Scala集合架构
[ 41M] 13-20 不可变数组的定义和使用
[ 42M] 13-21 [重要!必掌握]可变数组的定义和使用
[ 37M] 13-22 不可变和可变Set的定义和使用
[ 37M] 13-23 [重要!必掌握]不可变和可变List的定义和使用
[ 21M] 13-24 List方法的补充
[ 43M] 13-25 [重要!必掌握]Tuple的定义和使用
[ 28M] 13-26 [重要!必掌握]不可变Map的定义和使用及使用注意事项
[ 18M] 13-27 可变Map的定义和使用
[8.7M] 13-28 隐式转换能为我们带来什么
[7.3M] 13-29 模式匹配概念的理解
[ 11M] 13-30 模式匹配之快速上手
[ 16M] 13-31 模式匹配之内容匹配
[ 14M] 13-32 模式匹配之守卫模式
[ 25M] 13-33 模式匹配之类型匹配
[ 24M] 13-34 模式匹配之Array匹配
[5.7M] 13-35 模式匹配之Tuple匹配
[ 22M] 13-36 模式匹配之List匹配
[ 15M] 13-37 模式匹配之class匹配
[5.7M] 13-38 [重要!必掌握]模式匹配之caseclass匹配
[ 17M] 13-39 模式匹配之结合Spark讲解
[ 26M] 13-40 模式匹配之Scala异常处理
[ 33M] 13-41 初识偏函数
[ 45M] 13-42 [重要!必掌握]偏函数剥丝抽茧迭代
14-高效简洁编程Scala进阶:如何熟练掌握Scala函数式编程&隐式转换/
[3.6M] 14-1 本章概览
[ 24M] 14-2 经典面试题之函数和方法的区别
[ 22M] 14-3 [重要!必掌握]方法与函数的转换
[ 24M] 14-4 [重要!必掌握]高阶函数定义及使用
[8.7M] 14-5 Currying定义及使用
[ 46M] 14-6 [重要!必掌握]经典面试题之自定义实现一些高阶算子
[ 26M] 14-7 高阶算子详解之map
[ 30M] 14-8 高阶算子详解之filter&foreach&结合map的综合使用
[ 20M] 14-9 高阶算子详解之flatter&flatMap
[8.5M] 14-10 高阶算子详解之reduce&reduceLeft&reduceRight(一定要体会中间过程的理解)
[ 10M] 14-11 高阶算子详解之fold&foldLeft&foldRight(一定要体会中间过程的理解)
[ 12M] 14-12 高阶算子详解之zip系列
[ 27M] 14-13 高阶算子详解之groupBy
[5.7M] 14-14 高阶算子详解之mapValues
[ 42M] 14-15 高阶算子详解之排序系列
[ 20M] 14-16 高阶算子详解之算子综合实操
[3.5M] 14-17 注意一个小小的面试题
[8.0M] 14-18 隐式转换能为我们带来什么
[ 35M] 14-19 [重要!必掌握] 隐式转换函数的定义和使用
[ 20M] 14-20 [重要!必掌握]隐式转换函数的封装
[ 30M] 14-21 隐式类的定义和使用
[7.8M] 14-22 隐式类的封装
[ 32M] 14-23 隐式参数的定义和使用
15-高效简洁编程Scala进阶:如何熟练掌握Scala泛型/
[1.8M] 15-1 本章概览
[ 22M] 15-2 Java泛型基础回顾
[ 20M] 15-3 Java泛型上下限回顾
[ 39M] 15-4 Java中两种不同的排序
[ 25M] 15-5 Scala中泛型类的定义和使用
[ 19M] 15-6 Scala泛型上下限
[ 46M] 15-7 [重要!必掌握]Scala视图界定
[ 31M] 15-8 [重要!必掌握]Scala泛型结合隐式转换的使用
[8.6M] 15-9 Scala中的逆变和协变
16-高效简洁编程Scala实战:基于Akka编程模型实战通信项目/
[2.0M] 16-1 本章概览
[7.1M] 16-2 Akka概述
[ 36M] 16-3 剖析Actor模型工作机制
[9.0M] 16-4 需求分析
[ 46M] 16-5 功能实现之启动NN和DN
[ 19M] 16-6 功能实现之DN向NN建立连接并发送注册消息
[ 21M] 16-7 功能实现之封装消息
[ 11M] 16-8 功能实现之NN向DN发送注册成功消息
[ 35M] 16-9 功能实现之DN周期性的向NN发送心跳消息
[ 37M] 16-10 功能实现之NN定期检查超时的DN并移除
[ 11M] 16-11 功能实现之单机器多进程方式测试
17-大数据高手养成记之一:Hadoop源码研读,高薪秘笈/
[2.1M] 17-1 本章概览
[ 11M] 17-2 初识RPC
[ 58M] 17-3 自定义RPC协议实现
[ 77M] 17-4 如何以正确的姿势阅读源码&NN职责
[ 20M] 17-5 NameNode入口点函数
[ 40M] 17-6 NameNode核心成员变量初始化
[ 19M] 17-7 NameNodeHttpServer创建及启动
[ 20M] 17-8 加载命名空间
[ 16M] 17-9 创建NameNodeRpcServer
[ 18M] 17-10 NameNode启动流程梳理
[ 23M] 17-11 NameNode资源检查
[ 19M] 17-12 NameNode心跳检测
[ 26M] 17-13 NameNode安全模式
[ 45M] 17-14 DataNode启动宏观流程梳理
[ 37M] 17-15 startDataNode方法梳理
[ 23M] 17-16 初始化DataXceiverServer&DatanodeHttpServer&RPCServer
[ 55M] 17-17 DataNode向NameNode注册
[ 38M] 17-18 DataNode和NameNode的心跳处理
[ 82M] 17-19 MR作业提交流程源码分析
[ 43M] 17-20 MR作业提交流程小结
[ 76M] 17-21 MR作业提交流程之切片源码分析
[ 46M] 17-22 MapTask&ReduceTask执行流程源码分析
[ 45M] 17-23 提交作业到YARN上执行分析
18-大数据高手养成记之二:Hive源码研读,高薪秘笈/
[2.0M] 18-1 本章概览
[ 29M] 18-2 源码分析准备工作
[ 28M] 18-3 hiveconf的用法
[ 19M] 18-4 hivevar的用法
[6.2M] 18-5 &的用法
[ 36M] 18-6 寻找源码入口点
[ 39M] 18-7 CliDriver的run方法详解
[ 19M] 18-8 prompt的使用
[ 39M] 18-9 executeDriver方法剖析
[ 30M] 18-10 processCmd方法剖析
[ 43M] 18-11 processLocalCmd方法剖析
[ 13M] 18-12 SQL执行流程剖析
[ 49M] 18-13 逻辑执行计划&物理执行计划剖析
[ 34M] 18-14 compile方法剖析
[ 22M] 18-15 analyze方法剖析
[ 29M] 18-16 execute方法剖析
[ 27M] 18-17 Hive源码分析总结
19-完整Hadoop项目实战:基于Hadoop全流程实战离线数仓项目/
[2.8M] 19-1 本章概览
[ 30M] 19-2 大数据离线处理架构分析(上)
[ 21M] 19-3 大数据离线处理架构分析(下)
[ 44M] 19-4 CDN日志及指标了解
[ 53M] 19-5 日志类定义
[ 88M] 19-6 日志解析
[ 82M] 19-7 使用MR完成数据清洗功能
[ 30M] 19-8 数据质量指标统计
[ 36M] 19-9 数据清洗作业提交到YARN上运行
[ 27M] 19-10 创建Hive表并加载数据到表中
[ 22M] 19-11 维度指标分析
[ 26M] 19-12 通过JDBC查询Hive中的统计结果
[ 21M] 19-13 现在的处理方式引出的问题
[ 77M] 19-14 [重要]数仓分层(上)
[ 54M] 19-15 [重要]数仓分层(下)
[ 59M] 19-16 脚本封装etl及加载到hive表
[ 14M] 19-17 ODS层改进方案
[ 11M] 19-18 shell脚本补充
[ 19M] 19-19 调优之压缩能为我们带来什么
[ 37M] 19-20 调优之压缩如何选型
[ 61M] 19-21 调优之压缩的代码实现方式
[ 68M] 19-22 调优之压缩在MR中的使用
[ 41M] 19-23 调优之压缩在Hive中的使用
[ 41M] 19-24 调优之存储格式的使用(TextFile&RCFile)
[ 33M] 19-25 调优之存储格式的使用(ORC&Parquet)
[ 17M] 19-26 DWD层创建
[ 32M] 19-27 DWS&ADS层统计
[8.0M] 19-28 指标补充@it资源网ukoou.com
[ 15M] 19-29 业务数据构建数仓架构
[ 15M] 19-30 项目背景
[ 28M] 19-31 从产品角度梳理业务流转
[ 48M] 19-32 统计指标详解
[ 18M] 19-33 DataV使用
[ 38M] 19-34 ODS层实现
[ 28M] 19-35 DWD层实现
[ 33M] 19-36 ADS之学校使用情况
[ 22M] 19-37 ADS之全区平均时长分析-
[ 22M] 19-38 ADS之家长反馈情况-
[9.5M] 19-39 项目背景及相关指标
[ 11M] 19-40 项目表结构
[7.0M] 19-41 防控大屏效果展示
[ 36M] 19-42 健康码情况统计
[9.7M] 19-43 红黄绿码数情况统计
[ 24M] 19-44 完成率情况统计
[ 12M] 19-45 URL请求在DataV中的使用
20-大厂技术首选高薪必备:揭开Flink的神秘面纱/
[ 35M] 20-1 只熟悉Hadoop,就够了么?
[2.6M] 20-2 本章概览
[ 44M] 20-3 认识Flink
[ 26M] 20-4 部署应用到任意地方&运行任意规模应用
[ 27M] 20-5 Flink的起源及发展史
[ 49M] 20-6 Flink中的API
[ 24M] 20-7 Flink核心特性
[ 26M] 20-8 Flink对比Spark
21-批流一体丝滑开发体验:快速上手使用Flink进行编程/
[3.8M] 21-1 本章概览
[ 57M] 21-2 基于Flink官方提供的命令构建Flink应用程序
[ 59M] 21-3 基于IDEA+Maven构建Flink应用程序的本地开发环境
[ 21M] 21-4 词频统计案例需求分析
[ 61M] 21-5 Flink以批处理的方式实现功能开发
[ 21M] 21-6 开发重构之自定义Function的方式
[ 58M] 21-7 开发重构之Lambda表达式写法
[ 40M] 21-8 Flink以流处理的方式实现功能开发
[ 19M] 21-9 通过参数控制Flink以何种模式运行作业
[ 17M] 21-10 Flink对接socket数据并进行统计分析
22-工欲善其事必先利其器:Flink部署及作业运行/
[4.0M] 22-1 本章概览
[ 39M] 22-2 从宏观角度认识Flink架构
[ 50M] 22-3 再次认识JobManager和TaskManager
[ 46M] 22-4 Flink Standalone模式部署及Flink UI介绍
[ 16M] 22-5 flink run运行官方自带案例
[ 39M] 22-6 _补充_如何在本地运行环境中设定Flink WebUI
[ 20M] 22-7 动态传递参数给Flink应用程序改造
[ 13M] 22-8 使用Flink WebUI提交自己开发的Flink应用程序
[ 19M] 22-9 取消作业的两种方式
[ 38M] 22-10 _重要_如何使用命令行的方式提交Flink应用程序
[ 68M] 22-11 初探Flink集群部署模式
[ 26M] 22-12 Flink Standalone之Application Mode方式运行
[ 46M] 22-13 Flink on YARN之Application Mode方式运行
23-便捷接入处理输出:Source&Transformation&Sink编程/
[3.1M] 23-1 本章概览
[ 49M] 23-2 DataStream API编程规范以及DataStream是什么
[ 43M] 23-3 Flink多种执行环境的获取方式
[ 58M] 23-4 结合源码分析Data Source
[ 51M] 23-5 单并行度Source测试用例
[ 41M] 23-6 多并行度Source测试用例
[ 25M] 23-7 结合源码分析SourceFunction
[ 38M] 23-8 自定义实现单并行度数据源
[4.5M] 23-9 自定义实现多并行度数据源
[ 85M] 23-10 自定义数据源实现MySQL数据的读取
[9.5M] 23-11 认识Flink中有哪些Transformation算子
[ 48M] 23-12 Tranformation算子实操之map算子
[ 23M] 23-13 Tranformation算子实操之filter算子
[ 30M] 23-14 Tranformation算子实操之flatMap算子
[ 42M] 23-15 Tranformation算子实操之keyBy算子
[ 21M] 23-16 Tranformation算子实操之union算子
[ 32M] 23-17 Tranformation算子实操之connect算子
[ 82M] 23-18 Tranformation算子实操之自定义分区器
[ 51M] 23-19 DataStream分流
[ 28M] 23-20 认识Flink中的Sink
[ 39M] 23-21 Sink算子实操之print
[ 17M] 23-22 Sink算子实操之自定义Sink到终端
[ 55M] 23-23 Sink算子实操之自定义Sink到文件系统
[ 60M] 23-24 Flink处理结果输出到Redis中
[ 58M] 23-25 Flink处理结果输出到MySQL中
[ 25M] 23-26 Sink算子实操之输出到socket
24-玩转Flink项目实战之一:实时统计之商品分析/
[1.9M] 24-1 本章概览
[ 21M] 24-2 企业中基于Flink实时处理的架构分析
[ 17M] 24-3 需求分析
[ 16M] 24-4 本地开发环境搭建
[ 25M] 24-5 项目日志字段说明及生产数据注意事项
[ 38M] 24-6 对接数据及清洗
[ 16M] 24-7 日期格式清洗
[ 10M] 24-8 统计结果
[ 17M] 24-9 统计结果入Redis库
[ 24M] 24-10 自定义RedisSink
[ 50M] 24-11 实现改造并进行统计结果的diff
[ 14M] 24-12 拓展
25-工欲善其事必先利其器:Kafka架构&核心术语&部署&监控/
[3.4M] 25-1 本章概览
[ 31M] 25-2 认识JMS
[ 36M] 25-3 通过官网的介绍知晓Kafka是什么
[ 14M] 25-4 自我语言总结Kafka是什么
[ 13M] 25-5 Kafka在大数据中的典型使用场景screenflow
[ 44M] 25-6 图解Kafka架构
[8.1M] 25-7 -1 动起我们的小手进行单节点单Kafka的部署
[ 81M] 25-8 -2 动起我们的小手进行单节点单Kafka的部署
[ 40M] 25-9 kafka-topics命令行核心参数讲解
[ 51M] 25-10 Kafka Topic命令行操作
[ 32M] 25-11 Kafka生产者消费者命令行操作
[ 31M] 25-12 动起我们的小手进行单节点多Kafka的部署
[ 17M] 25-13 单节点多Kafka脚本命令测试
[ 36M] 25-14 Kafka监控部署及使用
26-深度剖析Kafka内部机制:生产者&Broker&消费者/
[4.7M] 26-1 本章概览
[ 52M] 26-2 [经典面试题必掌握]生产者消息发送流程
[ 56M] 26-3 生产者消息发送流程核心参数详解
[ 73M] 26-4 生产者API开发之普通异步发送
[ 33M] 26-5 生产者API开发之普通异步发送代码重构
[ 25M] 26-6 生产者API开发之带回调的异步发送
[ 12M] 26-7 生产者API开发之同步发送
[ 24M] 26-8 Kafka的分区机制能为我们带来什么
[ 35M] 26-9 Kafka分区策略结合源码分析
[ 55M] 26-10 Kafka分区策略结合源码分析进行功能验证
[ 29M] 26-11 Kafka自定义分区器功能开发及测试
[ 40M] 26-12 Kafka性能调优参数在代码中的使用
[ 38M] 26-13 [经典面试题必掌握]谈谈你对Kafka中的副本以及同步副本的看法
[ 59M] 26-14 [经典面试题必掌握]谈谈你对Kafka中的acks的看法
[9.2M] 26-15 [经典面试题必掌握]谈谈你对Kafka中的消费语义的看法
[ 52M] 26-16 精准一次消费实现之幂等性
[ 27M] 26-17 精准一次消费实现之事务
[ 27M] 26-18 精准一次消费实现之事务功能开发及测试
[6.2M] 26-19 Kafka中Topic内的Partition中数据的有序性
[ 69M] 26-20 Kafka相关信息在ZK上的存储机制
[ 21M] 26-21 Leader选择与ZK的关系
[ 26M] 26-22 Kafka副本机制
[ 37M] 26-23 Kafka数据存储机制
[115M] 26-24 Kafka数据存储机制更深入讲解
[ 34M] 26-25 Kafka核心参数讲解
[ 44M] 26-26 Kafka为什么使用的是pull的消费方式
[ 13M] 26-27 有了消费者之后为什么还需要消费者组
[ 20M] 26-28 消费者组和Topic的关系
[ 38M] 26-29 Kafka消费流程
[103M] 26-30 结合源码了解GroupCoordinator初始化过程
[ 60M] 26-31 消费者API编程之单消费者消费所有分区数据(上)
[ 57M] 26-32 消费者API编程之单消费者消费所有分区数据(下)
[ 29M] 26-33 消费者API编程之消费指定分区数据
[ 20M] 26-34 消费者API编程之多消费者消费各自分区数据
[ 53M] 26-35 Kafka分区策略之Range
[ 26M] 26-36 Kafka的Rebalance机制
[ 58M] 26-37 根据源码描述测试Range的分区策略及Rebalance
[ 16M] 26-38 统一思想完成其他策略的验证
[ 31M] 26-39 认识__consumer_offsets
[ 49M] 26-40 Kafka offset管理之自动提交
[ 16M] 26-41 Kafka offset管理之手动提交
[ 24M] 26-42 offset管理不当带来的隐患
27-经典Kafka CP整合使用:Kafka整合外部系统/
[1.6M] 27-1 本章概览
[ 27M] 27-2 认识Kafka在离线&实时处理处理架构中的位置
[ 34M] 27-3 Flume Sink到Kafka方案理解
[ 44M] 27-4 Flume Sink到Kafka功能开发及测试
[ 33M] 27-5 Flume KafkaSource对接到终端功能开发及测试
[ 55M] 27-6 Flink KafkaSource解读
[ 29M] 27-7 Flink KafkaSource功能开发及测试
[ 31M] 27-8 Flink KafkaSink功能开发及测试
28-玩转Flink项目实战之二:实时统计之商品分析(对接Kafka)/
[1.6M] 28-1 本章概览
[9.5M] 28-2 架构及内容介绍
[ 53M] 28-3 Flink接入Kafka数据
[ 20M] 28-4 重构代码
[ 69M] 28-5 Flink Stream关联MySQL数据操作
[ 58M] 28-6 Flink Asynchronous IO
[ 80M] 28-7 Flink异步IO读取MySQL的数据
29-时间对实时处理的影响:Flink时间语义&Window&Watermark/
[5.1M] 29-1 本章概览
[ 81M] 29-2 揭开Flink时间语义的面纱
[ 29M] 29-3 时间语义如何选择呢
[ 20M] 29-4 Window在实时计算中的地位
[ 28M] 29-5 Window的分类
[ 39M] 29-6 Window Assigners的职责及对应Window的分类
[ 21M] 29-7 Tumbling Window
[ 38M] 29-8 Sliding Windows
[ 26M] 29-9 Session Windows
[ 46M] 29-10 动手实操之CountWindow
[ 43M] 29-11 动手实操之TumblingWindow
[ 21M] 29-12 动手实操之SlidingWindow
[ 10M] 29-13 动手实操之SessionWindow
[ 44M] 29-14 Flink支持的WindowFunction
[ 45M] 29-15 WindowFunction动手实操之ReduceFunction
[ 62M] 29-16 WindowFunction动手实操之AggregateFunction
[ 46M] 29-17 WindowFunction动手实操之ProcessWindowFunction
[8.6M] 29-18 WindowFunction动手实操之AllWindowFunction
[ 76M] 29-19 WindowFunction动手实操之全量配合增量使用
[ 25M] 29-20 引入WM
[ 22M] 29-21 WM策略
[ 75M] 29-22 WM策略代码演示
[ 54M] 29-23 测试数据的WM
[ 47M] 29-24 [重要]综合编程之滚动窗口
[ 21M] 29-25 [重要]综合编程之滑动窗口
[ 91M] 29-26 [重要]数据延迟&乱序解决方案
30-Flink容错核心状态管理:状态在Flink中的应用/
[2.9M] 30-1 本章概览@it资源网
[ 26M] 30-2 初识State
[ 62M] 30-3 自定义完成类似Flink状态管理的功能
[ 94M] 30-4 Flink KeyedState的使用
[ 71M] 30-5 _重要_Flink Operator State的使用并体会Flink State的强大特性
[ 99M] 30-6 Flink ValueState编程
[102M] 30-7 Flink State Ttl编程
[ 29M] 30-8 process方法的用法一
[ 24M] 30-9 process方法的用法二
[ 45M] 30-10 process方法的用法三
[ 71M] 30-11 Checkpoint配置参数
[116M] 30-12 Flink Task重启策略
[ 70M] 30-13 _重要_Flink State Backend
31-玩转Flink项目实战之三:实时统计之数据大盘/
[2.6M] 31-1 本章概览
[ 60M] 31-2 多个Flink整合Kafka应用程序代码存在的问题
[ 28M] 31-3 读取配置文件中的参数
[ 37M] 31-4 Flink对接Kafka代码重构V1
[ 15M] 31-5 Flink对接Kafka代码重构V2
[ 27M] 31-6 [重要] Flink EOS
[ 29M] 31-7 [重要] Flink EOS再次剖析
[ 46M] 31-8 Flink EOS代码开发及本地测试并打包
[ 18M] 31-9 Flink EOS全流程在服务器上测试
[ 32M] 31-10 Flink checkpoint vs savepoint
32-Flink更加精简的开发方式:Flink Table & SQL API/
[3.3M] 32-1 本章概览
[ 48M] 32-2 Flink Table API&SQL概述及依赖
[ 34M] 32-3 Concepts&Common API
[ 78M] 32-4 Dynamic Tables
[ 90M] 32-5 DataStream和Table之间的相互转换
[ 53M] 32-6 Table API编程范式
[ 48M] 32-7 Table API&SQL Query
[ 68M] 32-8 创建Table对象
[ 67M] 32-9 创建Table对象续
[ 41M] 32-10 获取到SQL中用到的表名或者视图名
[ 41M] 32-11 临时表vs永久表
[ 28M] 32-12 初始Connector
[ 78M] 32-13 csv格式数据处理(上)
[ 38M] 32-14 csv格式数据处理(下)
[111M] 32-15 json格式数据处理
[ 80M] 32-16 Kafka Connector的使用
[ 81M] 32-17 时间语义在DDL中如何定义
[ 64M] 32-18 Upsert Kafka Connector的使用
[ 57M] 32-19 JDBC Connector的使用
[ 19M] 32-20 HBase Connector的使用
[ 12M] 32-21 拓展之开发实时处理平台
[ 98M] 32-22 自定义UDF函数之ScalarFunction
[ 64M] 32-23 自定义UDF函数之AggregateFunction
[ 53M] 32-24 自定义UDF函数之TableFunction
[ 23M] 32-25 SQL常用Query
[ 15M] 32-26 sql-client的用法
[ 60M] 32-27 Windowing TVF之TUMBLE
[ 35M] 32-28 Windowing TVF之HOP
[ 56M] 32-29 Window Top-N
33-数据采集神器Flink CDC:基于Flink CDC 进行实时数据采集/
[1.2M] 33-1 本章概览
[ 11M] 33-2 实时数据采集场景介绍
[ 19M] 33-3 Canal原理
[ 81M] 33-4 Canal部署及使用
[ 58M] 33-5 Canal编程
[ 16M] 33-6 Canal编程测试
[ 33M] 33-7 Flink CDC概述
[ 44M] 33-8 DataStream API对接CDC
[ 13M] 33-9 CDC从什么位置开始读取数据设置
[ 54M] 33-10 自定义定制开发输出样式
[ 73M] 33-11 FlinkCDC源码修改
[ 31M] 33-12 FlinkCDC对接sql方式
34-玩转Flink项目实战之四:实时统计之直播榜分析/
[1.4M] 34-1 本章概览
[ 30M] 34-2 背景及数据准备
[ 49M] 34-3 功能实现之数据接入
[ 60M] 34-4 功能实现之数据处理及写入
[ 49M] 34-5 可视化框架部署
[ 14M] 34-6 可视化大屏制作
[5.3M] 34-7 Flink处理过程简单化带来的好处
35-战斗民族开源神器ClickHouse:揭开CH的神秘面纱&数据类型&内置函数/
[3.2M] 35-1 本章概览
[ 11M] 35-2 产生背景
[ 35M] 35-3 OLAP特性
[ 19M] 35-4 列式存储特性
[ 40M] 35-5 ClickHouse部署
[ 31M] 35-6 ClickHouse核心目录
[ 22M] 35-7 Clickhouse-client命令参数
[ 19M] 35-8 ClickHouse官方数据使用说明
[ 12M] 35-9 ClickHouse跑分
[ 10M] 35-10 数据类型
[ 18M] 35-11 数值类型之整型
[ 16M] 35-12 数值类型之浮点型
[ 42M] 35-13 [重要]数值类型之Decimal
[6.5M] 35-14 布尔类型
[ 21M] 35-15 [重要]String和FixedString类型
[8.6M] 35-16 UUID类型
[ 38M] 35-17 [重要]日期和时间类型
[ 23M] 35-18 Array类型
[ 15M] 35-19 Tuple类型
[7.9M] 35-20 Map类型
[ 21M] 35-21 算数函数
[8.5M] 35-22 比较函数
[7.9M] 35-23 逻辑函数
[ 15M] 35-24 取整函数
[ 18M] 35-25 类型转换函数
[ 15M] 35-26 条件函数
[ 15M] 35-27 URL函数
[ 17M] 35-28 字符串函数
[ 28M] 35-29 日期时间函数
36-ClickHouse核心DDL&DML:库&表&视图的使用/
[1.5M] 36-1 本章概览
[ 22M] 36-2 DDL之创建数据库
[ 39M] 36-3 DDL之创建表
[6.0M] 36-4 DDL之删除表
[ 29M] 36-5 DDL之修改表
[8.0M] 36-6 DDL之重命名表
[6.1M] 36-7 DDL之清空表数据
[ 32M] 36-8 DML之插入数据
[ 16M] 36-9 DML之修改和删除数据
[ 33M] 36-10 分区表的创建及加载数据
[ 11M] 36-11 分区表删除分区
[ 13M] 36-12 分区表复制分区
37-ClickHouse核心引擎分析:各家族核心引擎使用及选型/
[2.3M] 37-1 本章概览
[ 13M] 37-2 表引擎概览
[9.6M] 37-3 Log Engine Family的共性
[ 23M] 37-4 TinyLog引擎
[ 24M] 37-5 Stripelog引擎
[ 19M] 37-6 Log引擎
[ 22M] 37-7 [重要]Log Engine Family总结
[ 13M] 37-8 表引擎之Integrations概览
[ 54M] 37-9 表引擎Integrations之HDFS引擎
[ 25M] 37-10 表引擎Integrations之MySQL引擎
[9.8M] 37-11 数据库引擎之MySQL引擎
[ 21M] 37-12 表引擎Special之File引擎
[ 17M] 37-13 表引擎Special之Merge引擎
[ 12M] 37-14 表引擎Special之Memory引擎
[ 15M] 37-15 MergeTree Engine概览
[ 28M] 37-16 MergeTree Engine核心语法详解
[ 23M] 37-17 [重要]MergeTree Engine非分区表功能测试
[ 24M] 37-18 [重要]MergeTree Engine日期类型分区表功能测试
[ 53M] 37-19 [重要]MergeTree Engine执行流程分析
[ 42M] 37-20 ReplacingMergeTree引擎
[ 28M] 37-21 ReplacingMergeTree引擎带ver的使用
[ 43M] 37-22 SummingMergeTree引擎
38-经典CH整合Flink编程:元数据管理&整合Flink开发/
[2.0M] 38-1 本章概览
[ 29M] 38-2 [重要]元数据在大数据中的作用
[ 45M] 38-3 ClickHouse元数据之tables
[ 33M] 38-4 ClickHouse元数据之columns
[ 15M] 38-5 ClickHouse元数据之表相关元数据
[8.9M] 38-6 ClickHouse元数据之执行相关元数据
[ 11M] 38-7 ClickHouse元数据之内置不同种类的维度表元数据
[7.6M] 38-8 ClickHouse元数据之用户&角色&权限&配额元数据
[6.0M] 38-9 ClickHouse元数据之其他元数据
[ 24M] 38-10 ClickHouse JDBC编程概述
[ 42M] 38-11 ClickHouse JDBC编程
[ 69M] 38-12 Flink整合ClickHouse写操作
[ 17M] 38-13 Flink整合ClickHouse读操作
39-玩转Flink项目实战之五:基于Flink和ClickHouse构建实时数据分析/
[5.2M] 39-1 本章概览
[9.8M] 39-2 实战功能改善
[ 41M] 39-3 场景一之功能实现一
[ 78M] 39-4 场景一之功能实现二
[ 80M] 39-5 场景一之功能实现三
[ 20M] 39-6 场景一之扩展
[ 16M] 39-7 场景二需求分析
[ 67M] 39-8 场景二之功能实现一
[ 56M] 39-9 场景二之功能实现二
[ 59M] 39-10 场景二之功能实现三
[ 11M] 39-11 场景二之功能扩展
[ 17M] 39-12 可视化
[ 15M] 39-13 总结与扩展
40-揭开数据湖的神秘面纱:数据湖开源产品Hudi的使用/
[2.5M] 40-1 本章概览
[ 36M] 40-2 引入数据湖
[ 22M] 40-3 常用数据湖框架对比
[ 30M] 40-4 初识Hudi
[ 40M] 40-5 再次认识Hudi
[ 23M] 40-6 Hudi发展历史
[ 52M] 40-7 核心概念之TimeLine
[ 75M] 40-8 快速使用Spark写入数据到Hudi
[ 46M] 40-9 核心概念之File Layouts
[ 24M] 40-10 核心概念之Index
[ 55M] 40-11 核心概念之Index Type
[ 26M] 40-12 核心概念之Table Type(COW)
[ 34M] 40-13 核心概念之Table Type(MOR)
[7.4M] 40-14 核心概念之Table Type(对比)
[ 39M] 40-15 核心概念之Query Types
[ 22M] 40-16 核心概念之其他
[ 41M] 40-17 Hudi整合Flink SQL快速入门
[ 11M] 40-18 Flink SQL对接Kafka数据
[146M] 40-19 Flink SQL对接Kafka数据落入Hudi
41-玩转Flink项目实战之六:基于Flink和Hudi的数据湖构建项目/
[1.6M] 41-1 本章概览
[ 14M] 41-2 回顾离线处理架构
[ 25M] 41-3 引入Hudi后的架构
[ 14M] 41-4 架构中重要环节的补充说明
[ 63M] 41-5 Flink中Catalog使用
[ 64M] 41-6 Flink对接catalog之读取Hive数据
[ 29M] 41-7 Flink对接catalog之写入Hive数据
[ 24M] 41-8 Hudi版本升级
[ 46M] 41-9 Flink整合Hive Catalog
[ 19M] 41-10 表结构讲解
[ 21M] 41-11 分层
[ 29M] 41-12 CDC层建设
[ 20M] 41-13 产生数据
[ 79M] 41-14 订单表ODS层建设
[9.7M] 41-15 商品表ODS层建设
[ 11M] 41-16 订单详情表ODS层建设
[ 28M] 41-17 DWD层建设思路
[ 30M] 41-18 订单相关DWD层建设思路_1
[ 40M] 41-19 ADS层建设
[ 21M] 41-20 总结





评论0