
课程介绍
多层次构建企业级大数据平台, 成就全能型大数据开发。本课程从零开始,深入讲解了集群监控与治理、数据采集与处理以及数据落地及应用,带你全面构建大数据平台核心能力,多纬度,高效构建你的“全能型”技能体系。
相关推荐
9大业务场景实战Hadoop+Flink,完成大数据能力进修
极客时间 – 大数据训练营
集海量数据存储、数据采集、数据处理、任务调度、数据开发、数据应用于一体的大数据平台是各个公司进行大规模数据处理所必备的基础能力。
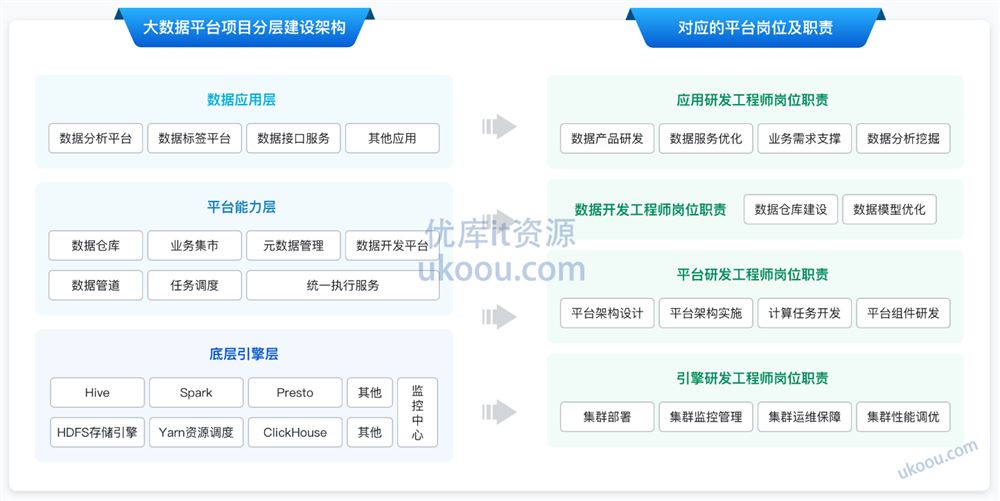
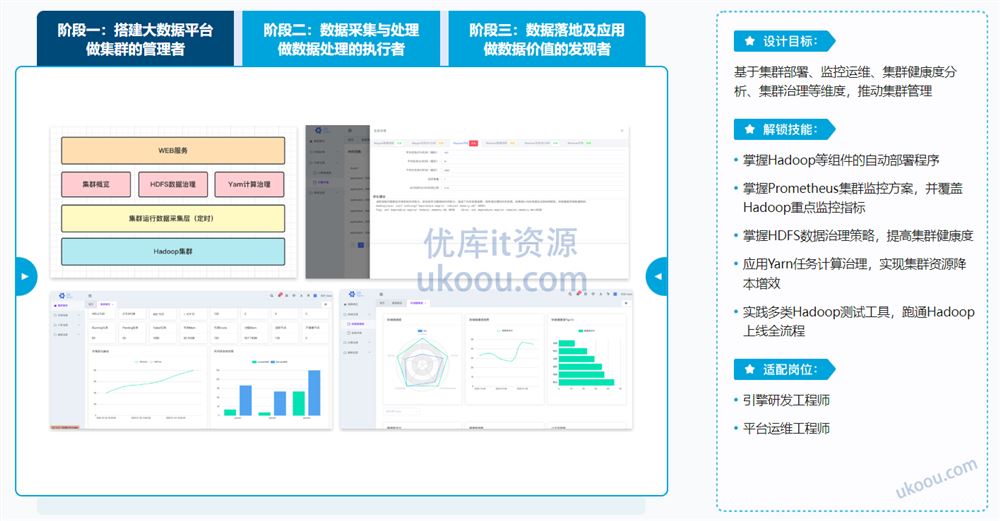
基于集群部署、监控运维、集群健康度分析、集群治理等维度,推动集群管理
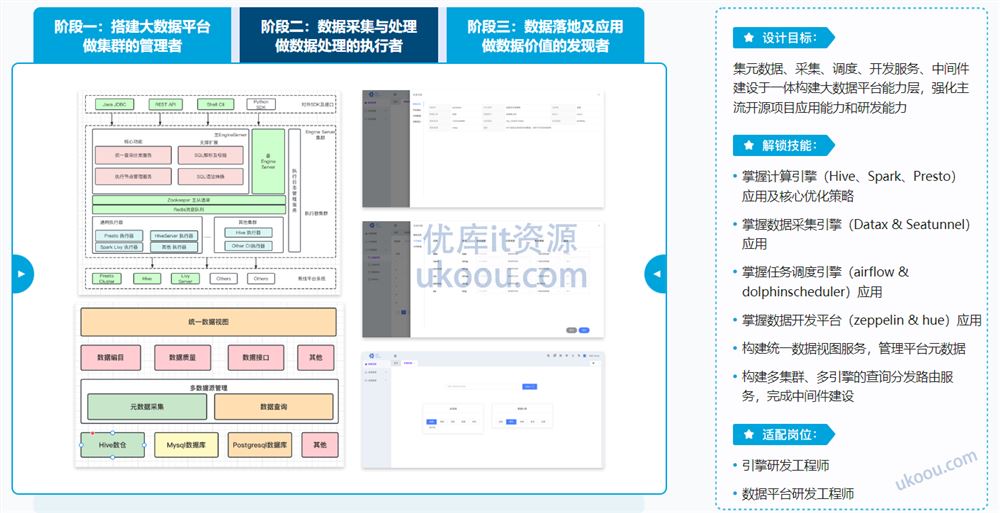
集元数据、采集、调度、开发服务、中间件建设于一体构建大数据平台能力层,强化主流开源项目应用能力和研发能力
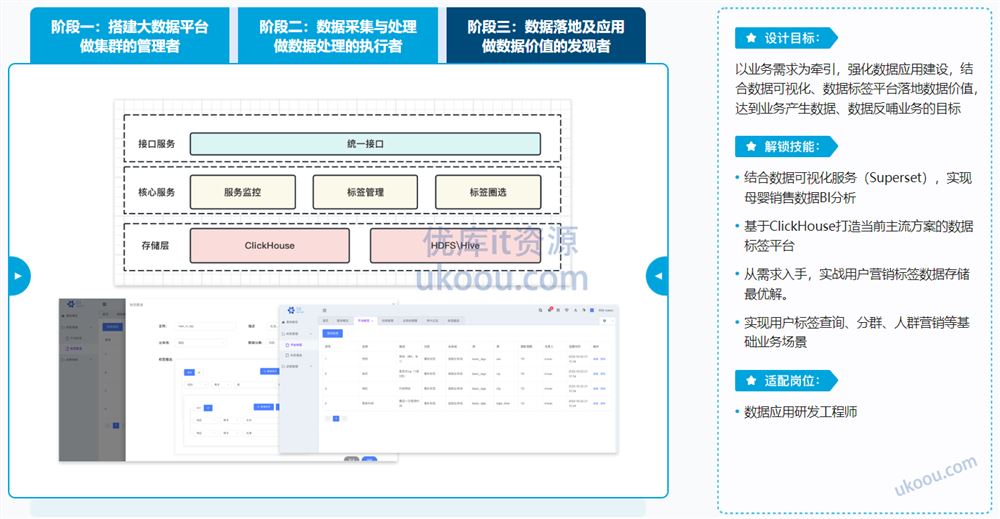
以业务需求为牵引,强化数据应用建设,结合数据可视化、数据标签平台落地数据价值,达到业务产生数据、数据反哺业务的目标
资源目录
.
1-你好,大数据平台!/
[ 29M] 1-1 做驾驭“多赛道” 的 “全能型” 大数据人才,获岗位自由切换和晋升“优先权”
[ 14M] 1-2 如何成为一个大数据工程师
[7.0M] 1-3 站在数据工程师角度看大数据平台
[ 25M] 1-4 一叶知秋:企业大数据平台初探
[8.3M] 1-5 浅谈大数据平台和数据中台的关系
2-大数据平台的地基:快速搞定Hadoop集群安装部署/
[3.6M] 2-1 阶段一:做集群的管理者
[ 11M] 2-2 拆解自动部署步骤
[ 46M] 2-3 JSch实现远程命令执行
[ 36M] 2-4 Freemarker实现配置自动生成
[ 32M] 2-5 核心模块:配置文件加载
[ 40M] 2-6 核心模块:机器初始化及免密
[ 41M] 2-7 核心模块:配置模板生成
[ 40M] 2-8 自动部署核心逻辑开发
[ 68M] 2-9 自动部署Hadoop集群
[3.2M] 2-10 本章小结
3-平台基础模块之监控和预警/
[ 13M] 3-1 监控系统的必要性
[ 37M] 3-2 Prometheus实现机器监控
[ 28M] 3-3 PromQL查询及报警配置
[ 13M] 3-4 再谈Prometheus架构
[6.1M] 3-5 Hadoop重点监控指标梳理
[ 25M] 3-6 实战:Hadoop重点监控采集及监控图表配置
[ 37M] 3-7 扩展:自定义Exporter开发
[3.2M] 3-8 本章小结
4-平台底层引擎之HDFS存储治理/
[8.8M] 4-1 认识数据治理
[ 10M] 4-2 数仓分层策略
[6.5M] 4-3 HDFS元数据分析
[ 20M] 4-4 FSImage元数据分析
[ 23M] 4-5 实战:遍历HDFS存储空间
[8.5M] 4-6 Hadoop3新特性:EC纠删码技术
[ 27M] 4-7 EC转换命令测试
[8.2M] 4-8 为什么HDFS不适合存储小文件
[5.8M] 4-9 如何解决小文件存储的问题
[ 53M] 4-10 实战:Text类型小文件合并程序开发
[ 16M] 4-11 实战:ORC类型小文件合并程序开发
[3.6M] 4-12 本章小结
5-平台底层引擎之YARN计算治理/
[9.0M] 5-1 认识计算治理
[ 15M] 5-2 YARN的三类调度策略
[ 47M] 5-3 CapacityScheduler配置实战
[5.4M] 5-4 任务分析组件:Dr Elephant
[ 19M] 5-5 DrElephant采集任务运行信息
[4.1M] 5-6 本章小节
6-企业数据平台建设第一步:打造集群管理平台/
[8.1M] 6-1 设计一个集群管理平台
[6.4M] 6-2 数据采集和集群概览功能详解
[5.0M] 6-3 HDFS数据治理模块详解
[4.7M] 6-4 YARN计算治理模块详解
[ 55M] 6-5 核心功能:HDFS JMX采集
[ 66M] 6-6 核心功能:Yarn JMX采集
[ 11M] 6-7 HDFS健康度评分指标
[ 18M] 6-8 HDFS基础数据采集详解
[ 94M] 6-9 核心功能:HDFS 数据详情采集
[ 14M] 6-10 认识规则引擎
[ 47M] 6-11 规则引擎Drools实战
[ 71M] 6-12 核心功能:HDFS健康度评分
[ 12M] 6-13 YARN健康度评分指标
[ 67M] 6-14 核心功能:YARN健康度评分
[ 52M] 6-15 集群概览服务及接口
[ 26M] 6-16 存储计算详情列表服务及接口
[ 60M] 6-17 健康度评分服务及接口
[ 40M] 6-18 审计日志服务及接口
[ 30M] 6-19 集群管理平台前端开发及联调
7-扩展:Hadoop如何开发和测试/
[ 17M] 7-1 Hadoop开发与测试
[ 16M] 7-2 基准测试工具:TestDFSIO
[ 20M] 7-3 基准测试工具:NNBench
[9.3M] 7-4 基准测试工具:MRBench
[ 26M] 7-5 Yarn SLS测试实战
[8.7M] 7-6 Hadoop上线流程
[5.1M] 7-7 本章小结@it资源网
8-扩展:面试题和分布式系统延伸/
[7.9M] 8-1 逃不过的面试
[ 11M] 8-2 常见Hadoop面试题(一)
[7.7M] 8-3 常见Hadoop面试题(二)
[4.0M] 8-4 Prometheus面试题
[ 16M] 8-5 聊聊分布式系统
[9.7M] 8-6 再看HDFS存储架构
[ 17M] 8-7 分布式系统的中心化问题
[ 11M] 8-8 再谈CAP定理
[ 11M] 8-9 阶段小结
9-企业数据平台建设第二步: 实现统一数据视图/
[ 10M] 9-1 阶段二:做数据处理的执行者
[9.4M] 9-2 阶段二学习路线图
[ 15M] 9-3 为什么建设统一数据视图
[ 11M] 9-4 元数据管理的三个问题
[ 13M] 9-5 统一数据视图架构及模块划分
[ 66M] 9-6 数据源模块实体及链接参数抽象
[ 78M] 9-7 核心功能:多数据源管理及验证
[ 48M] 9-8 核心功能:多数据源链接抽象
[ 65M] 9-9 核心功能:多数据源元数据查询功能
[ 49M] 9-10 核心功能:数据查询功能开发
[ 63M] 9-11 核心功能:自动更新库表信息
[ 20M] 9-12 数据编目实体介绍
[ 42M] 9-13 数据编目服务开发
[ 13M] 9-14 数据质量及接口管理模块介绍
[ 38M] 9-15 数据质量及接口服务开发
[ 33M] 9-16 元数据管理服务前端开发
[ 24M] 9-17 番外篇:元数据体系架构的演进
[ 13M] 9-18 番外篇:Apache Atlas介绍
[9.1M] 9-19 番外篇:DataHub介绍
[ 16M] 9-20 本章小结
10-平台能力建设之计算引擎/
[认准一手完整 www.ukoou.com]
[6.1M] 10-1 大数据计算引擎学习路线
[ 14M] 10-2 MapReduce架构图解
[ 26M] 10-3 实战:MapReduce实现WordCount程序
[9.1M] 10-4 Hive架构图解
[ 19M] 10-5 实战:Hive基础命令及JDBC操作
[ 16M] 10-6 Spark架构及提交流程
[ 19M] 10-7 Spark核心数据结构
[ 36M] 10-8 实战:Spark实现WordCount程序
[ 28M] 10-9 实战:Spark DataFrame操作
[9.9M] 10-10 Spark常见优化策略
[ 15M] 10-11 Presto架构介绍
[ 13M] 10-12 Presto内存模型介绍
[9.8M] 10-13 实战:Presto命令行及JDBC操作
[5.4M] 10-14 Hive TestBench介绍
[ 14M] 10-15 扩展:再看MapReduce性能
[ 16M] 10-16 扩展:Shuffle的演进
[ 13M] 10-17 扩展:SQL join优化演进
[7.4M] 10-18 番外篇:数据血缘之Hive Hook
[ 38M] 10-19 番外篇:实战HiveHook表级别数据血缘
[4.0M] 10-20 番外篇:数据血缘之Presto EventListener
[ 60M] 10-21 番外篇:实战PrestoEventListener获取运行SQL
[7.3M] 10-22 番外篇:数据血缘之SparkListener
[5.2M] 10-23 本章小结
11-平台能力建设之数据采集服务/
@it资源网ukoou.com
[ 11M] 11-1 为什么要建设数据管道
[ 12M] 11-2 DataX架构介绍
[ 54M] 11-3 实战:Datax实现Mysql和HDFS数据采集
[ 30M] 11-4 实战:Datax增量采集配置
[7.9M] 11-5 SeaTunnel架构介绍
[ 31M] 11-6 实战:SeaTunnel实现Mysql数据采集
[ 15M] 11-7 实战:SeaTunnel增量采集配置
[ 10M] 11-8 重探SeaTunnel设计
[ 12M] 11-9 SeaTunnel的Zeta引擎
[ 11M] 11-10 如何设计一个数据管道系统
[ 12M] 11-11 本章小结
12-平台能力建设之任务调度服务/
[ 10M] 12-1 为什么需要调度系统
[8.8M] 12-2 Airflow介绍
[ 36M] 12-3 Airflow WebUI介绍
[ 41M] 12-4 Airflow DAG实战
[ 12M] 12-5 DolphinScheduler介绍
[ 30M] 12-6 Dolphinscheduler工作流配置实战
[ 24M] 12-7 Dolphinscheduler集成Datax
[ 34M] 12-8 Dolphinscheduler任务参数
[ 38M] 12-9 Dolphinscheduler特殊任务类型
[ 30M] 12-10 Dolphinscheduler资源中心
[ 28M] 12-11 Dolphoinscheduler接口
[ 21M] 12-12 如何设计一个调度系统
[ 26M] 12-13 本章小结
13-平台能力建设之数据开发平台/
[7.2M] 13-1 为什么需要大数据开发平台
[ 19M] 13-2 Zeppelin&Hue介绍
[ 23M] 13-3 实战Hue操作HDFS和Hiveserver2
[ 12M] 13-4 如何设计一个大数据开发平台
14-扩展:深入了解SQL的解析和优化/
[6.0M] 14-1 Sql on Hadoop引擎介绍
[ 12M] 14-2 Sql on Hadoop引擎平台使用痛点
[8.9M] 14-3 统一执行服务介绍
[ 13M] 14-4 Calcite介绍
[ 18M] 14-5 Calcite架构及集成场景图解
[9.6M] 14-6 SQL解析简介
[ 66M] 14-7 实战:Calcite解析SQL
[ 42M] 14-8 实战:Calcite自定义语法一
[ 57M] 14-9 实战:Calcite自定义语法二
[ 52M] 14-10 实战:Calcite支持自定义csv数据源
[ 11M] 14-11 SQL优化简介
[ 10M] 14-12 SQL常用优化规则
[ 12M] 14-13 SQL优化核心步骤
[ 41M] 14-14 实战:Calcite进行CBO优化
[ 11M] 14-15 本章小结
15-企业数据平台建设第三步: 统一数据查询入口/
[ 22M] 15-1 统一执行服务介绍及技术架构
[ 22M] 15-2 核心数据表设计与开发
[ 11M] 15-3 gRPC介绍
[8.8M] 15-4 grpc通信消息体设计与开发
[ 57M] 15-5 高可用方案介绍
[ 28M] 15-6 主从选举代码开发
[115M] 15-7 Router核心分发模块开发
[ 59M] 15-8 执行节点核心模块开发
[ 52M] 15-9 辅助分析功能开发
[103M] 15-10 Presto执行节点开发
[ 95M] 15-11 查询提交方法及接口开发
[ 42M] 15-12 查询接口测试
[ 55M] 15-13 HiveServer2执行节点开发
[9.2M] 15-14 Apache Livy服务介绍
[ 68M] 15-15 Spark On Livy执行节点开发
[ 50M] 15-16 Livy Client模块开发
[ 84M] 15-17 RouterJDBC模块开发
[ 17M] 15-18 RouterJDBC测试程序开发
[ 48M] 15-19 RouterClient可执行客户端开发
[9.4M] 15-20 RouterClient功能测试
16-平台能力建设之数据仓库/
[ 24M] 16-1 认识数据仓库
[ 14M] 16-2 什么是数据集市
[ 17M] 16-3 数据仓库架构
[ 17M] 16-4 为什么需要数据建模
[ 13M] 16-5 数据仓库分层
[ 15M] 16-6 数据仓库常见概念
[ 20M] 16-7 常见的数据建模方法
[ 13M] 16-8 维度建模详解
[ 11M] 16-9 维度建模示例
[ 23M] 16-10 离线数仓&实时数仓
[ 13M] 16-11 常见数据仓库建设规范
[ 22M] 16-12 简谈数据治理
[9.5M] 16-13 数据质量评估
[9.0M] 16-14 数据质量管理流程
[ 10M] 16-15 数据质量监控框架及解决方案总结
[ 12M] 16-16 初探DataOPS
[7.4M] 16-17 数据仓库本章小结
17-企业数据平台应用第一步:数据分析与可视化/
[ 13M] 17-1 阶段三:做数据价值发现的引领者
[6.5M] 17-2 阶段三学习路线
[9.9M] 17-3 为什么需要数据分析和可视化平台
[ 11M] 17-4 SuperSet介绍
[ 33M] 17-5 实战:SuperSet图表配置操作
[ 12M] 17-6 销售数据分析业务场景
[ 22M] 17-7 母婴数据集导入大数据集群
[ 37M] 17-8 母婴数据分析图表
[ 12M] 17-9 如何设计一个数据可视化平台
18-扩展:标签系统技术选型之ClickHouse/
[ 16M] 18-1 什么是标签
[ 17M] 18-2 透过用户画像看标签
[ 15M] 18-3 为什么要建设标签体系
[ 18M] 18-4 标签平台建设技术选型
[ 55M] 18-5 三类Bitmap操作实战
[ 14M] 18-6 ClickHouse介绍
[ 24M] 18-7 ClickHouse基本操作
[ 14M] 18-8 ClickHouse核心架构
[ 36M] 18-9 MergeTree引擎详解
[ 24M] 18-10 HDFS、Hive数据导入至ClickHouse
[ 13M] 18-11 ClickHouse JDBC实战
[ 12M] 18-12 ClickHouse Bitmap操作
[8.4M] 18-13 本章小结
19-企业数据平台应用第二步:数据标签体系与用户标签实战/
[9.1M] 19-1 标签平台技术架构及模块划分
[4.8M] 19-2 核心数据表介绍与开发
[ 15M] 19-3 标签存储设计
[ 31M] 19-4 测试数据创建
[ 54M] 19-5 开发:测试数据录入ClickHouse一
[ 35M] 19-6 开发:测试数据录入ClickHouse二
[ 41M] 19-7 表达式转换为Clickhouse SQL一
[ 39M] 19-8 表达式转换为Clickhouse SQL二
[ 26M] 19-9 标签查询核心功能
[ 22M] 19-10 标签查询接口测试
[ 45M] 19-11 重点接口监控实现
[ 14M] 19-12 标签平台前端集成
[ 16M] 19-13 课程小结
资源目录截图






评论0